Как компьютеры понимают отдельные символы
С самого начала курса Вы написали несколько интересных программ, но все они обработали только один вид данных - числа. Как Вы знаете, (Вы можете видеть это везде), многие компьютерные данные не являются числами: имена, фамилии, адреса, названия, стихи, научные статьи, электронные письма, судебные решения, признания в любви и многое, многое другое.
Все эти данные должны храниться, вводиться, выводиться, просматриваться и преобразовываться современными компьютерами, как и любые другие данные, независимо от того, являются ли они односимвольными или многотомными энциклопедиями.
Как это возможно?
Как Вы можете сделать это в Python? Это то, что мы сейчас обсудим. Давайте начнем с того, как компьютеры понимают отдельные символы.
Компьютеры хранят символы в виде чисел. Каждый символ, используемый компьютером, соответствует уникальному номеру, и наоборот. Это распределение должно включать больше символов, чем Вы могли ожидать. Многие из них невидимы для людей, но необходимы для компьютеров.
Некоторые из этих символов называются белыми символами (пробелами), некоторые называются управляющими символами, поскольку их целью является управление устройствами ввода/вывода.
Примером белого символа, который полностью невидим невооруженным глазом, является специальный код или пара кодов (разные операционные системы могут по-разному относиться к этой проблеме), которые используются для обозначения концов строк в текстовых файлах.
Люди не видят этот знак (или эти знаки), но могут наблюдать эффект от их использования в случае прерывания линий.
Мы можем создать практически любое количество пар символ-число, но жизнь в мире, в котором каждый тип компьютера использует разную кодировку символов, была бы не очень удобной. Эта система привела к необходимости введения универсального и общепринятого стандарта, применяемого (почти) всеми компьютерами и операционными системами во всем мире.
Есть стандарт ASCII (сокращенно Американский стандартный код для обмена информацией), является наиболее широко используемым, и можно предположить, что почти все современные устройства (например, компьютеры, принтеры, мобильные телефоны, планшеты и т.д.) используют этот код.
Код предоставляет место для 256 различных символов, но нас интересуют только первые 128. Если Вы хотите увидеть, как строится код, посмотрите на таблицу ниже. Нажмите на таблицу, чтобы увеличить ее. Посмотрите на нее внимательно - есть некоторые интересные факты. Посмотрите на код наиболее распространенного символа - пробел. Это 32.
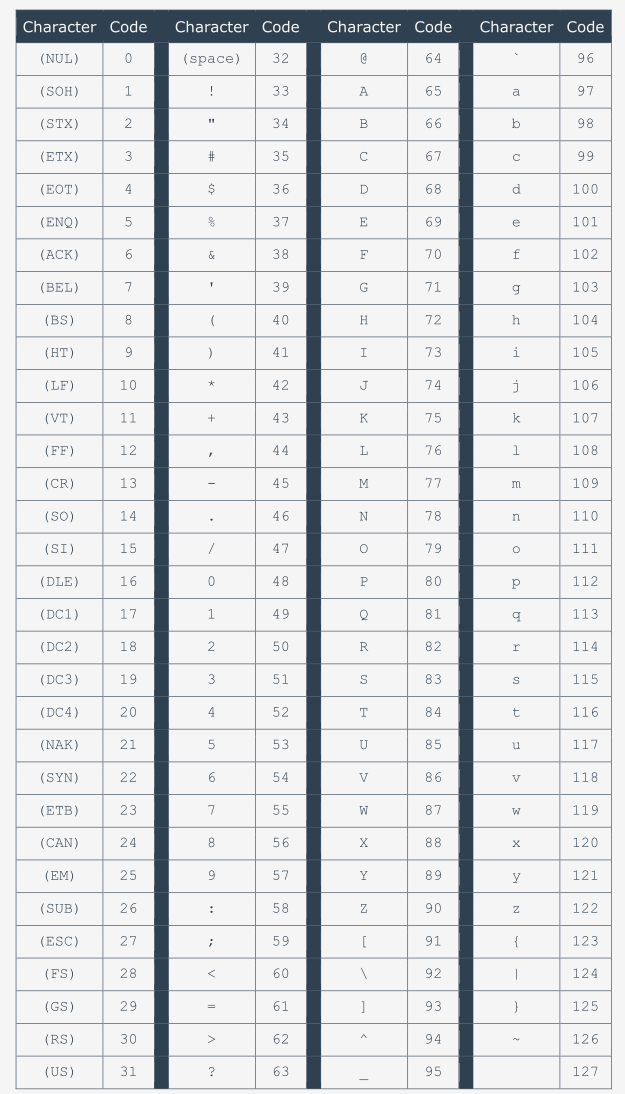
Теперь проверьте код строчной буквы a. Это 97. А теперь найдите заглавную букву A. Ее код 65. Теперь посчитайте разницу между кодом a и A. Это равно 32. Это код пробела. Интересно, не правда ли?
Также обратите внимание, что буквы расположены в том же порядке, что и в латинском алфавите.