Cómo las computadoras entienden los caracteres individuales
Has escrito algunos programas interesantes desde que comenzó este curso, pero todos ellos han procesado solo un tipo de datos: los números. Como sabes (puedes ver esto en todas partes), muchos datos de la computadora no son números: nombres, apellidos, direcciones, títulos, poemas, documentos científicos, correos electrónicos, sentencias judiciales, confesiones de amor y mucho, mucho más.
Todos estos datos deben ser almacenados, ingresados, emitidos, buscados y transformados por computadoras como cualquier otro dato, sin importar si son caracteres únicos o enciclopedias de múltiples volúmenes.
¿Como es posible?
¿Cómo puedes hacerlo en Python? Esto es lo que discutiremos ahora. Comencemos con cómo las computadoras entienden los caracteres individuales.
Las computadoras almacenan los caracteres como números. Cada carácter utilizado por una computadora corresponde a un número único, y viceversa. Esta asignación debe incluir más caracteres de los que podrías esperar. Muchos de ellos son invisibles para los humanos, pero esenciales para las computadoras.
Algunos de estos caracteres se llaman espacios en blanco, mientras que otros se nombran caracteres de control, porque su propósito es controlar dispositivos de entrada / salida.
Un ejemplo de un espacio en blanco que es completamente invisible a simple vista es un código especial, o un par de códigos (diferentes sistemas operativos pueden tratar este asunto de manera diferente), que se utilizan para marcar el final de las líneas dentro de los archivos de texto.
Las personas no ven este signo (o estos signos), pero pueden observar el efecto de su aplicación donde ven un salto de línea.
Podemos crear prácticamente cualquier cantidad de asignaciones de números con caracteres, pero la vida en un mundo en el que cada tipo de computadora utiliza una codificación de caracteres diferentes no sería muy conveniente. Este sistema ha llevado a la necesidad de introducir un estándar universal y ampliamente aceptado, implementado por (casi) todas las computadoras y sistemas operativos en todo el mundo.
El denominado ASCII (por sus siglas en íngles American Standard Code for Information Interchange). El Código Estándar Americano para Intercambio de Información es el más utilizado, y es posible suponer que casi todos los dispositivos modernos (como computadoras, impresoras, teléfonos móviles, tabletas, etc.) usan este código.
El código proporciona espacio para 256 caracteres diferentes, pero solo nos interesan los primeros 128. Si deseas ver cómo se construye el código, mira la tabla a continuación. Haz clic en la tabla para ampliarla. Mírala cuidadosamente: hay algunos datos interesantes. Observa el código del caracter más común: el espacio. El cual es el 32.
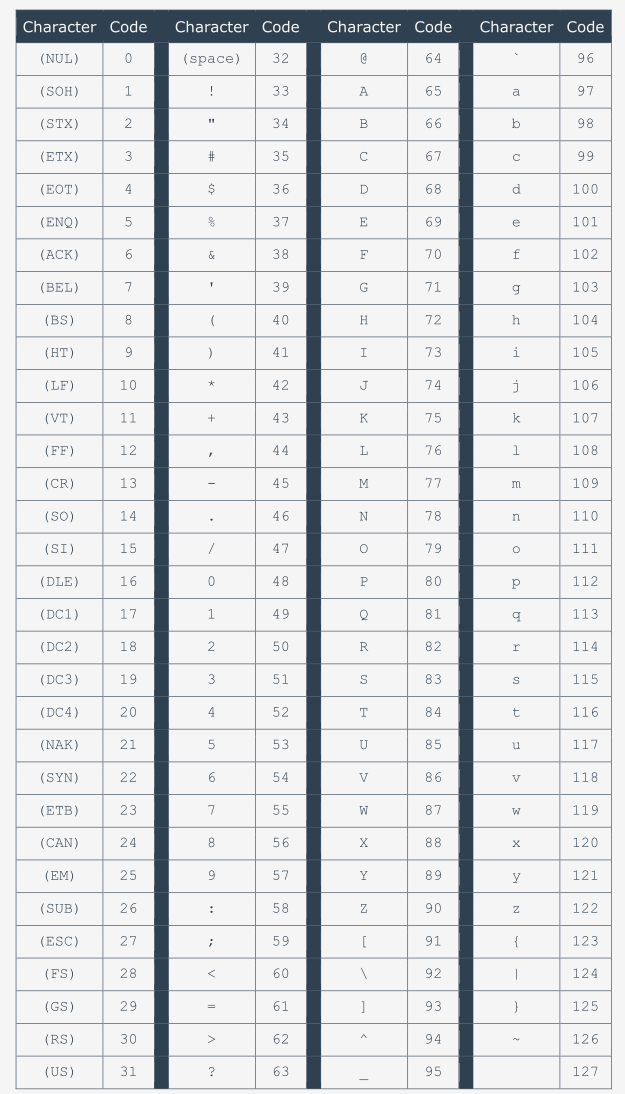
Ahora verifica el código de la letra minúscula a. El cual es 97. Ahora encuentra la A mayúscula. Su codigo es 65. Ahora calcula la diferencia entre el código de la a y la A. Es igual a 32. Ese es el códgo del espacio. Interesante, ¿no es así?
También ten en cuenta que las letras están ordenadas en el mismo orden que en el alfabeto latino.